서론
Elasticsearch를 처음 도입해야 하는 경우, 클러스터가 기존보다 더 좋은 성능이 나오게 하고 싶은 경우, index를 더 효율적으로 보관하고 싶은경우, 또는 여러가지 이유 등으로 Elastissearch를 사용하는 엔지니어라면 node 구성을 어떻게 하는 것이 좋을지를 한 번쯤은 고민해봤을 것이다.
최근 Elasticsearch의 클러스터 성능을 높이고 index를 더 효율적으로 보관하기 위해 여러가지 방법을 리서치를 했는데 이에 관한 내용을 게재해볼 예정이다.
이번에 게재할 내용은 Hot-Warm architecture로 index를 효율적으로 오래 보관하는 방법을 소개하고자 한다. 시계열성 index라면 도입해볼만 하다
Hot-Warm architecture를 테스트 해보고 싶다면 https://github.com/hgs0426/elastic-stack-example/tree/master/hot-warm-architecture 에서 스크립트를 받아서 실행시키된다. 스크립트를 통해 docker container로 구성된 클러스터를 쉽게 띄워볼 수 있다.

Hot-Warm architecture란, index의 사용빈도(즉, disk의 I/O 빈도)에 따라 tier를 나눠서 보관하는 방법이다. Tier로는 Hot과 Warm 필요하다면 Frozen까지 나눈다. 각 tier 의 memory : storage의 비는 Hot tier의 경우 1 : 30, Cold tier의 경우 1 : 160이 권장된다. 예를들어, data node를 구성할 때 RAM 16 (GB)인 경우 Hot tier의 경우에는 SSD로 480 (GB)를, Warm tier의 경우에는 HDD로 2.56 (TB)를 준비하면 된다.
| Tier | Goal | Storage | Memory:Storage ratio |
| Hot | Optimize for search | SSD SAN/DAS | 1:30 |
| Warm | Optimize for storage | HDD SAN/DAS | 1:160 |
| Frozen | Optimize for archive | Cheapest SAN/DAS | 1:1000+ |
시계열 Index인 경우에 도입을 고려해보자
Index가 시계열 데이터인 경우, 예를 들어 애플리케이션에서 발생하는 에러 로그라고 가정해보자. 최근의 로그일 수록 indexing과 디버깅을 위해 search가 빈번히 일어나기 때문에 Storage의 I/O 성능이 매우 중요하다. 때문에 SSD를 사용하는 것이 합리적이다.
비교적 오래된 로그라면 indexing은 전혀 일어나지 않고 가끔 search만 일어날 것이므로(즉, read-only index의 경우) HDD에 저장하는 것이 경제적이다.
로그가 매우 오래되었지만 아주 가끔 조회되는 경우에는 매우 값싼 디스크로 data node를 구성하면 될 것이다.
조회될 경우가 거의 없지만 삭제할 수 없는 데이터는 snapshot을 만들어서 NAS 등에 보관하면 될 것이다.
이처럼, 시계열 index의 경우에는 Hot-Warm architecture를 사용하는 것이 적합하고, index의 life cycle에 따라 Hot -> Warm -> Frozen Tier에 머물게 된다.
Hot-Warm architecture 를 만들어보자
우선 아래 1-1, 1-2 중 에 한 가지 방법으로 data node를 실행한다.
1-1. elasticsearch.yml에 설정
Data node의 설정 파일인 elasticsearch.yml 에서 아래와 같이 설정한다.
- Hot tier
// elasticsearch.yml
node.attr.box_type: hot
- Warm tier
// elasticsearch.yml
node.attr.box_type: warm
1-2. 실행할 때 옵션으로 준다.
- Hot tier
./bin/elasticsearch -Enode.attr.box_type=hot
- Warm tier
./bin/elasticsearch -Enode.attr.box_type=warm
2. index mapping시 Hot tier로 설정
bank_20191218 이라는 index를 생성할 때 "index.routing.allocation.require.box_type": "hot"를 설정해서 Hot tier의 index로 만든다.
PUT /bank_20191218
{
"settings": {
"number_of_shards": 5,
"number_of_replicas": 1,
"index.routing.allocation.require.box_type": "hot"
}
}
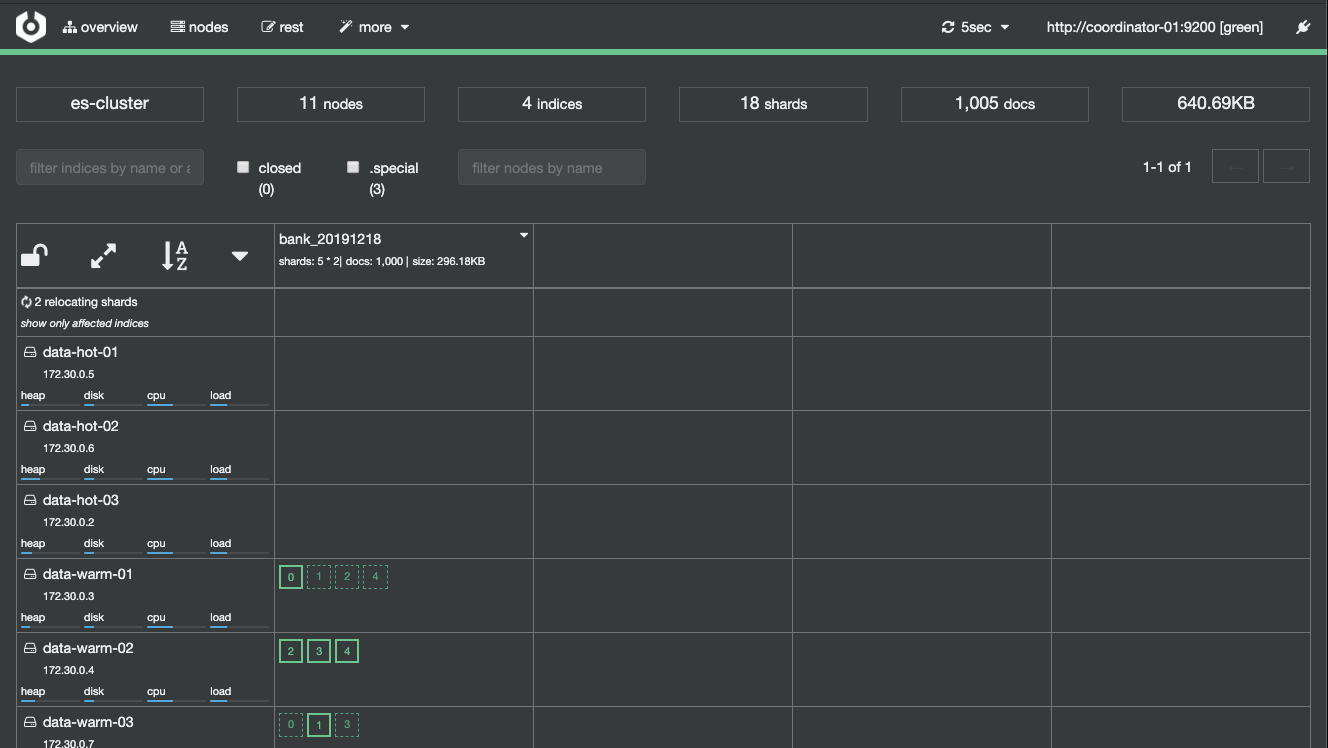
그러면, 아래 그림과 같이 Hot tier의 data node들에만 index가 저장된다. hot과 warm을 이런식으로 격리 시킬 수 있다.

3. iindex mapping시 Warm tier로 설정
일정 주기가 지나서 bank_20191218라는 index를 Warm tier로 옮기는 경우이다.
PUT /bank_20191218/_settings
{
"settings": {
"index.routing.allocation.require.box_type": "warm"
}
}
그러면, 아래 그림과 같이 Warm tier의 data node들에만 저장된다.
결론
Elasticsearch에 시계열 index를 저장하는 경우 Hot-Tier architecture를 도입하는 것을 고려해보자. Hot-Tier architecture를 도입함으로써 index를 더 오래 보관하고 조회할 수 있을 것으로 기대한다.
참고
[1] https://www.elastic.co/kr/webinars/elasticsearch-sizing-and-capacity-planning
[2] https://www.elastic.co/kr/blog/hot-warm-architecture-in-elasticsearch-5-x
'Elastic Stack' 카테고리의 다른 글
| Elasticsearch, Cluster는 어떻게 구성돼 있을까? (0) | 2019.12.27 |
|---|---|
| Elasticsearch-7.5.0, data backup, snapshot, restore (0) | 2019.12.16 |
| Elasticsearch-7.4.2, Docker container로 띄우기 (0) | 2019.11.28 |
| Elasticsearch-7.4.2, Ubuntu Server-18.04에 설치하기 (0) | 2019.11.27 |